Hey there, It's been a busy past month with festivals and getting my new home ready. Hence the delay.
Welcome back to the third part of the system design series. If you are a first-time visitor, You may like to look at my other blog posts in this series.
In my last blog, we learned about Domain Name Systems (DNS), Load Balancers, and clustering. and we briefly discussed the advantage and features of load balancers and clusters and how they differ from each other. We also covered the cases when these are required to be used in a system.
In this blog, we will try to cover the system design topic w.r.t. Caching, Content Delivery, and Proxies. let's get started.
Caching

A cache is a high-speed data storage layer that stores a subset of data, typically transient so that future requests for that data are served up faster than is possible by accessing the data’s primary storage location. Caching allows you to reuse previously retrieved or computed data efficiently.
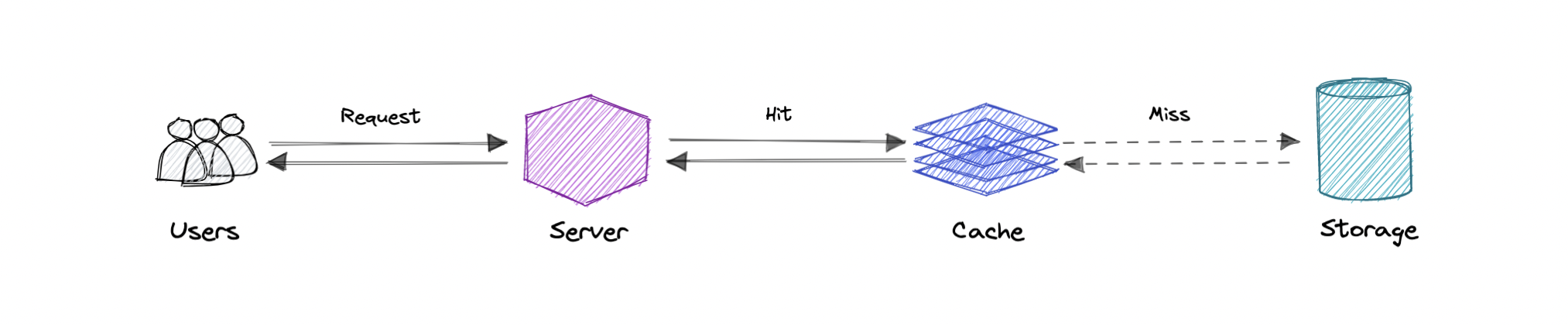
A cache's main purpose is to increase data retrieval performance by reducing the need to access the underlying data storage (databases) layer which is relatively slower. It prioritizes speed over capacity, Hence a cache typically stores a subset of data transiently, Unlike databases whose data is usually complete and durable but slower to access/update.
Caches work on the locality of reference principle or * principle of locality* which states that: The tendency of a processor to access the same set of memory locations repetitively over a short period is Higher. Or _ "recently requested data is likely to be requested again"._
Caching and Memory
A cache is a compact, fast-performing memory system (Like a computer's RAM) that stores data in hierarchies/levels. i.e. L1, L2, L3 ... Ln.
A cache even gets written on request, i.e. when there is an update in the data and new data needs to be saved to the cache, replacing the older data that was saved.
Cache read/written is always done one block at a time. Each block has a tag that contains the location where the data was stored. When data is requested from the cache, a search occurs through the tags to find the specific content that's needed in level one (L1) of the memory. If the correct data isn't found, more searches are conducted in L2.
If the data isn't found there, searches are continued in L3, then L4, and so on until it has been found, then, it's read and loaded. If the data isn't found in the cache at all, then it's written into it for quick retrieval the next time.
Cache hit and Cache miss
Cache hit
A cache hit describes the situation where content is successfully served from the cache. The tags are searched in the memory rapidly, and when the data is found and read, it's considered a cache hit.
Cold, Warm, and Hot Caches
A cache hit can also be described as cold, warm, or hot. In each of these, the speed at which the data is read is described.
A hot cache is an instance where data was read from the memory at the fastest possible rate. This happens when the data is retrieved from L1.
A cold cache is the slowest possible rate for data to be read, though, it's still successful so it's still considered a cache hit. The data is just found lower in the memory hierarchy such as in L3, or lower.
A warm cache is used to describe data that's found in L2 or L3. It's not as fast as a hot cache, but it's still faster than a cold cache. Generally, calling a cache warm is used to express that it's slower and closer to a cold cache than a hot one.
Cache miss
A cache miss refers to the instance when the memory is searched, and the data isn't found. When this happens, the content is transferred and written into the cache.
Cache Invalidation
Cache invalidation is a process where the computer system declares the cache entries as invalid and removes or replaces them. If the data is modified, it should be invalidated in the cache, if not, this can cause inconsistent application behavior. There are three kinds of caching systems:
Write-through cache
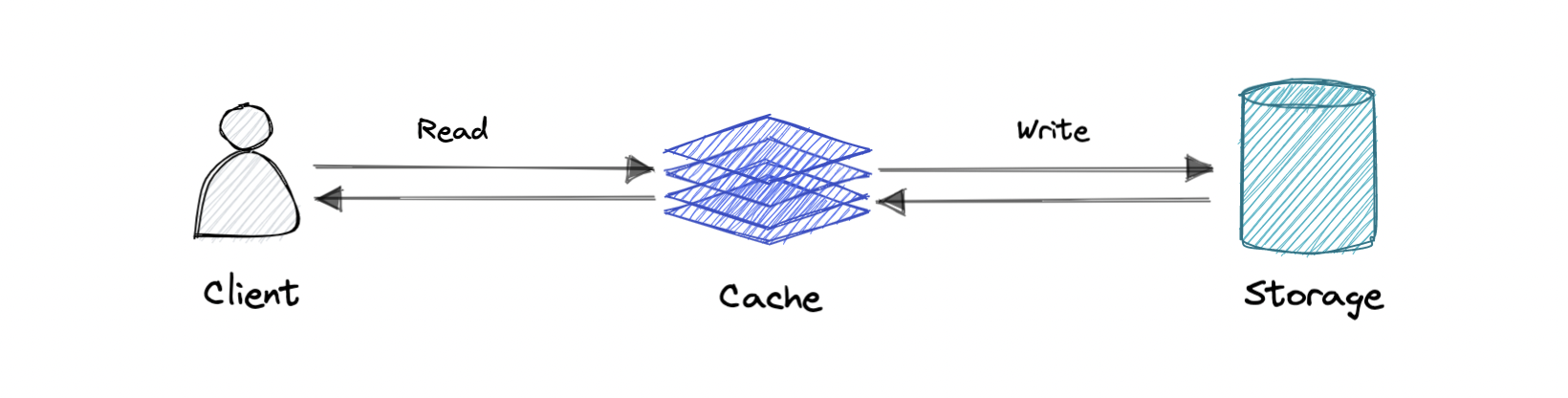
Data is written into the cache and the corresponding database simultaneously.
Pro: Fast retrieval, and complete data consistency between cache and storage.
Con: Higher latency for write operations.
Write-around cache
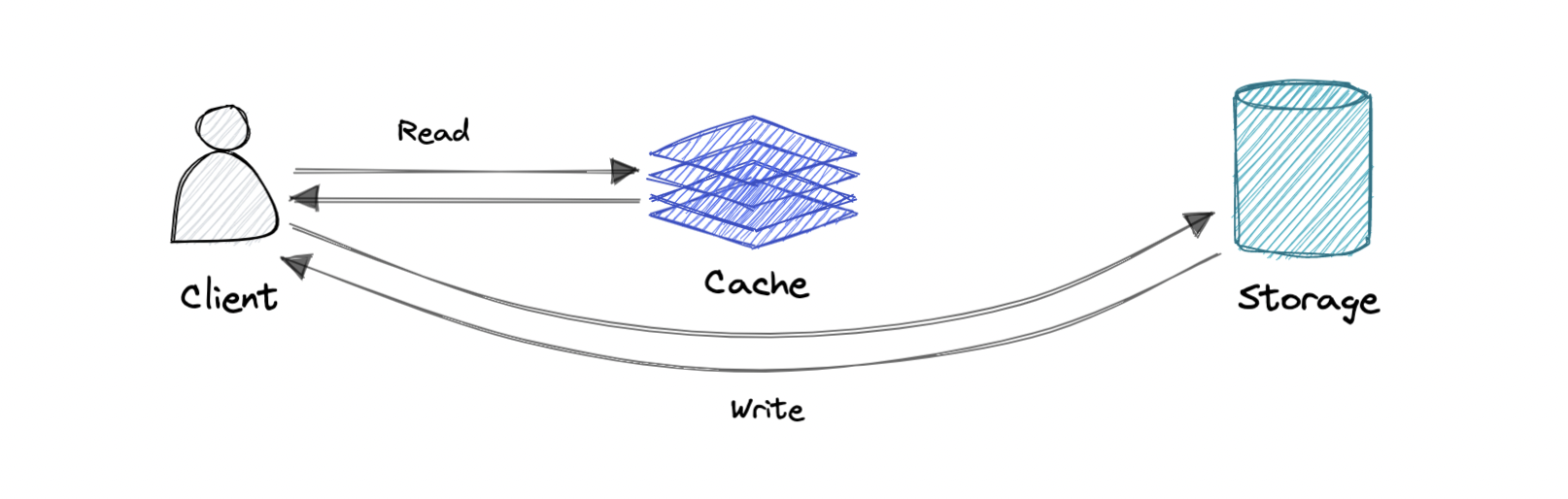
Where write directly goes to the database or permanent storage, bypassing the cache.
Pro: This may reduce latency.
Con: It increases cache misses because the cache system has to read the information from the database in case of a cache miss. As a result, this can lead to higher read latency in the case of applications that write and re-read the information quickly. Read happen from slower back-end storage and experiences higher latency.
Write-back cache
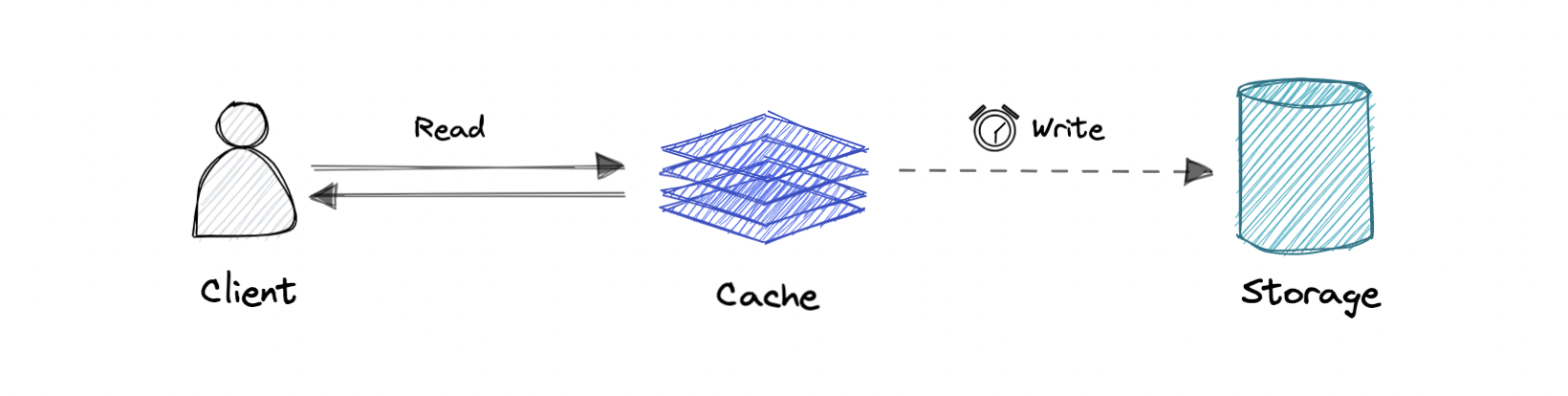
Where the write is only done to the caching layer and the write is confirmed as soon as the write to the cache completes. The cache then asynchronously syncs this write to the database.
Pro: This would lead to reduced latency and high throughput for write-intensive applications.
Con: There is a risk of data loss in case the caching layer crashes. We can improve this by having more than one replica acknowledging the write in the cache.
Eviction policies
Following are some of the most common cache eviction policies:
First In First Out (FIFO): The cache evicts the first block accessed first without any regard to how often or how many times it was accessed before.
Last In First Out (LIFO): The cache evicts the block accessed most recently first without any regard to how often or how many times it was accessed before.
Least Recently Used (LRU): Discards the least recently used items first.
Most Recently Used (MRU): Discards, in contrast to LRU, the most recently used items first.
Least Frequently Used (LFU): Counts how often an item is needed. Those that are used least often are discarded first.
Random Replacement (RR): Randomly selects a candidate item and discards it to make space when necessary.
Distributed Cache
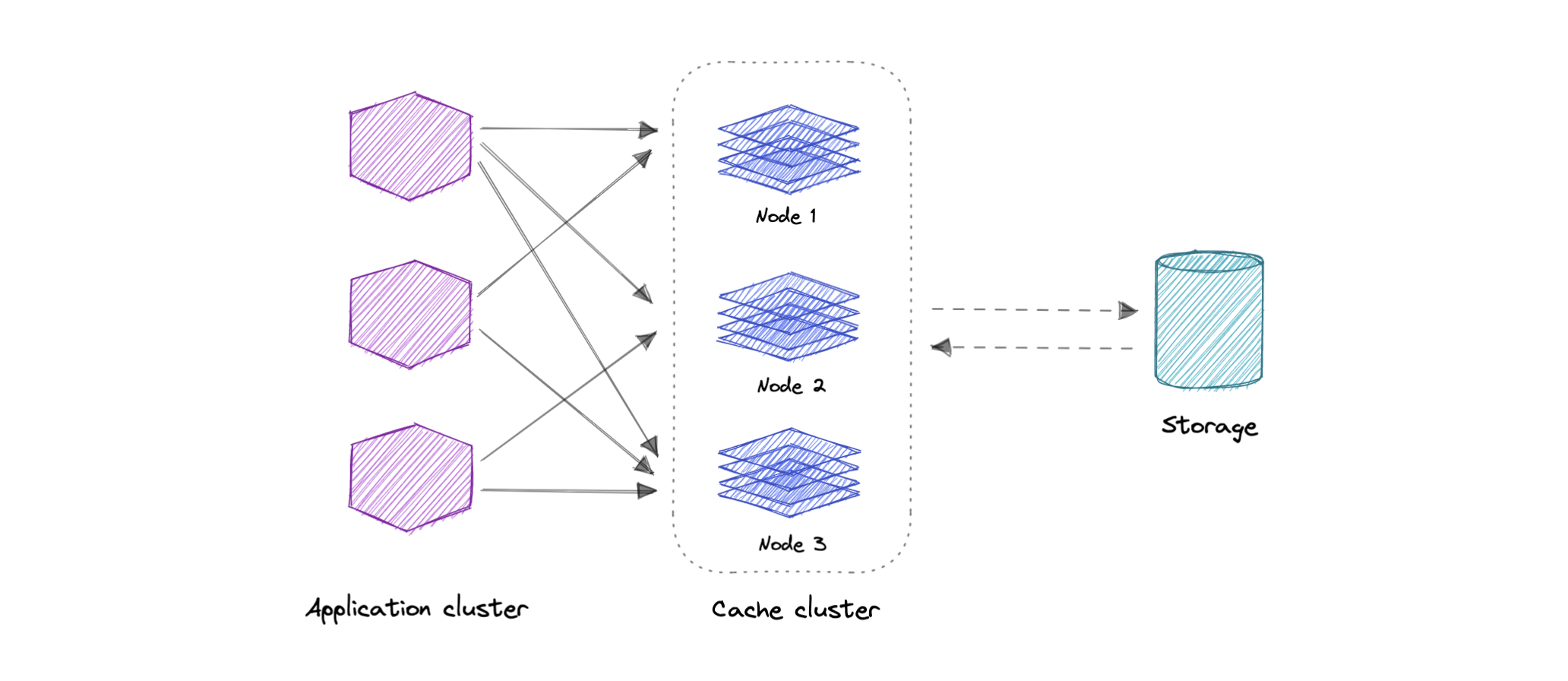
A distributed cache is a system that pools together the random-access memory (RAM) of multiple networked computers into a single in-memory data store used as a data cache to provide fast access to data. While most caches are traditionally in one physical server or hardware component, a distributed cache can grow beyond the memory limits of a single computer by linking together multiple computers.
Global Cache
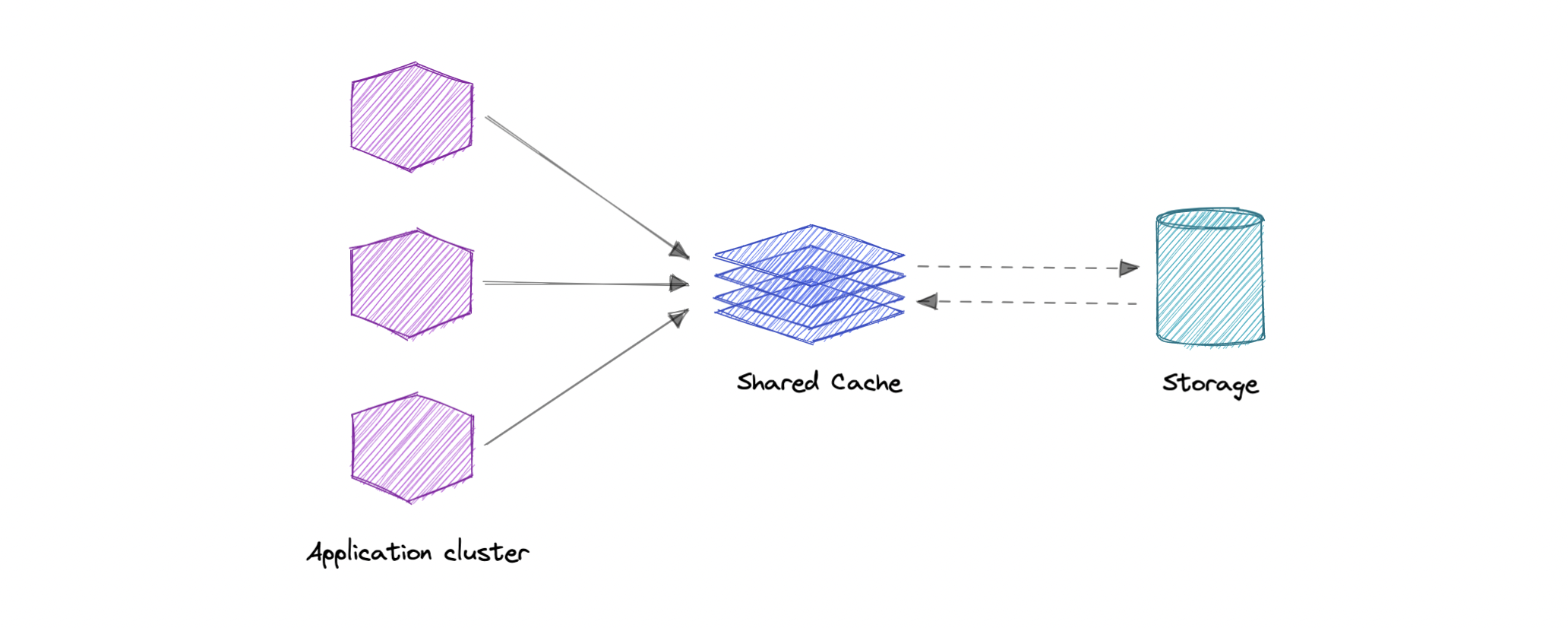
As the name suggests, we will have a single shared cache that all the application nodes will use. When the requested data is not found in the global cache, it's the cache's responsibility to find the missing piece of data from the underlying data store.
Use cases
Caching can have many real-world use cases such as:
When not to use caching?
Let's also look at some scenarios where we should not use cache:
Caching isn't helpful when it takes just as long to access the cache as it does to access the primary data store.
Caching doesn't work very well when requests have low repetition (higher randomness), because caching performance comes from repeated memory access patterns.
Caching isn't helpful when the data frequently changes, as the cached version gets out of sync, and the primary data store must be accessed every time.
It's important to note that a cache should not be used as permanent data storage. They are almost always implemented in volatile memory because it is faster, and thus should be considered transient.
Advantages
Below are some advantages of caching:
Examples
Here are some commonly used technologies for caching:
Content Delivery Network (CDN)
A content delivery network (CDN) is a geographically distributed and interconnected group of servers that work together to provide fast delivery of internet content. In general, static files like HTML/CSS/JS, photos, and videos (content in general) are served over CDN.
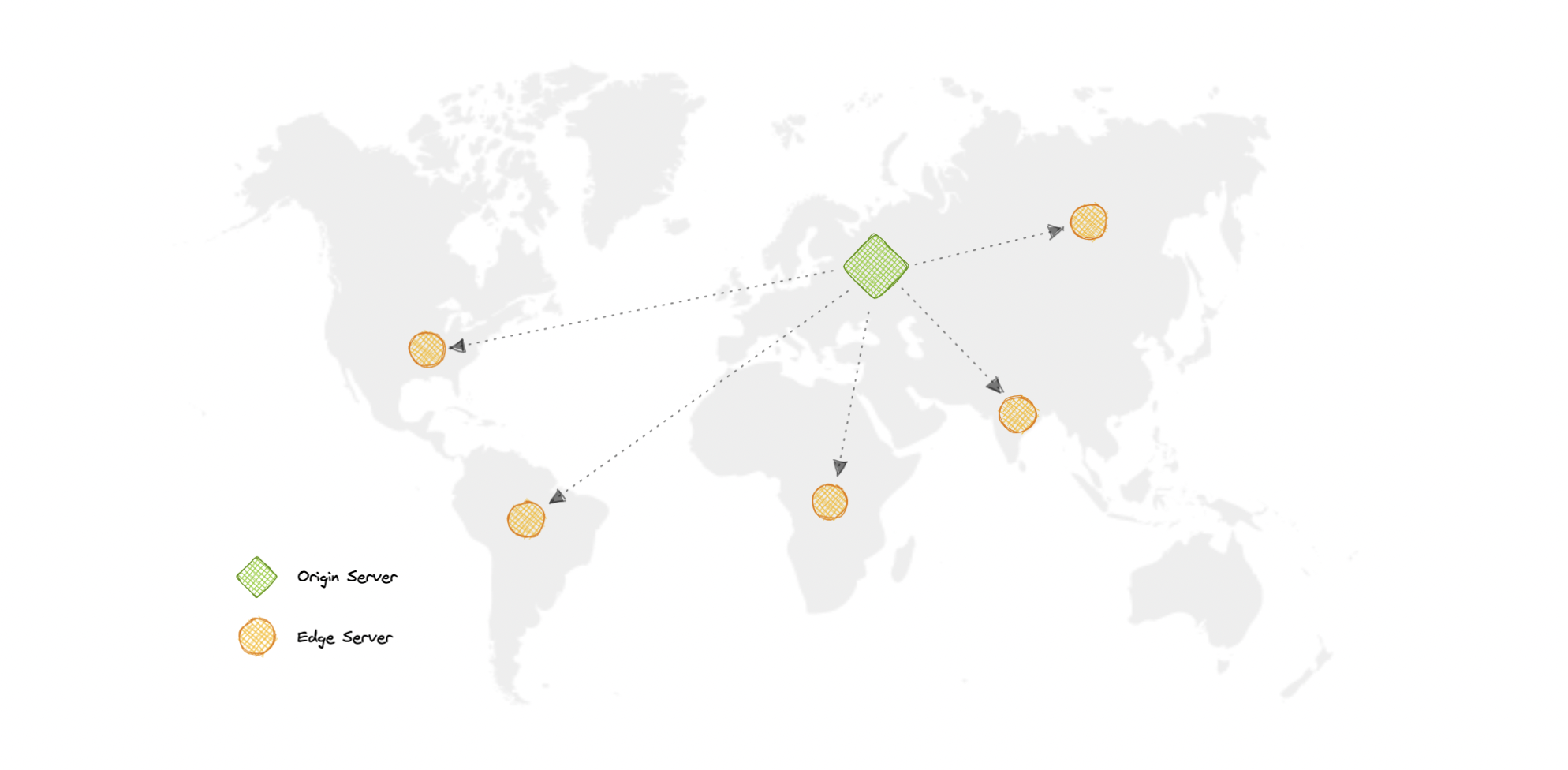
Why use a CDN?
A content Delivery Network (CDN) increases content availability while reducing bandwidth costs and improving security. Serving content from CDNs can significantly improve performance as users receive content from data centers close to them and our servers do not have to serve requests that the CDN fulfills.
How does a CDN work?
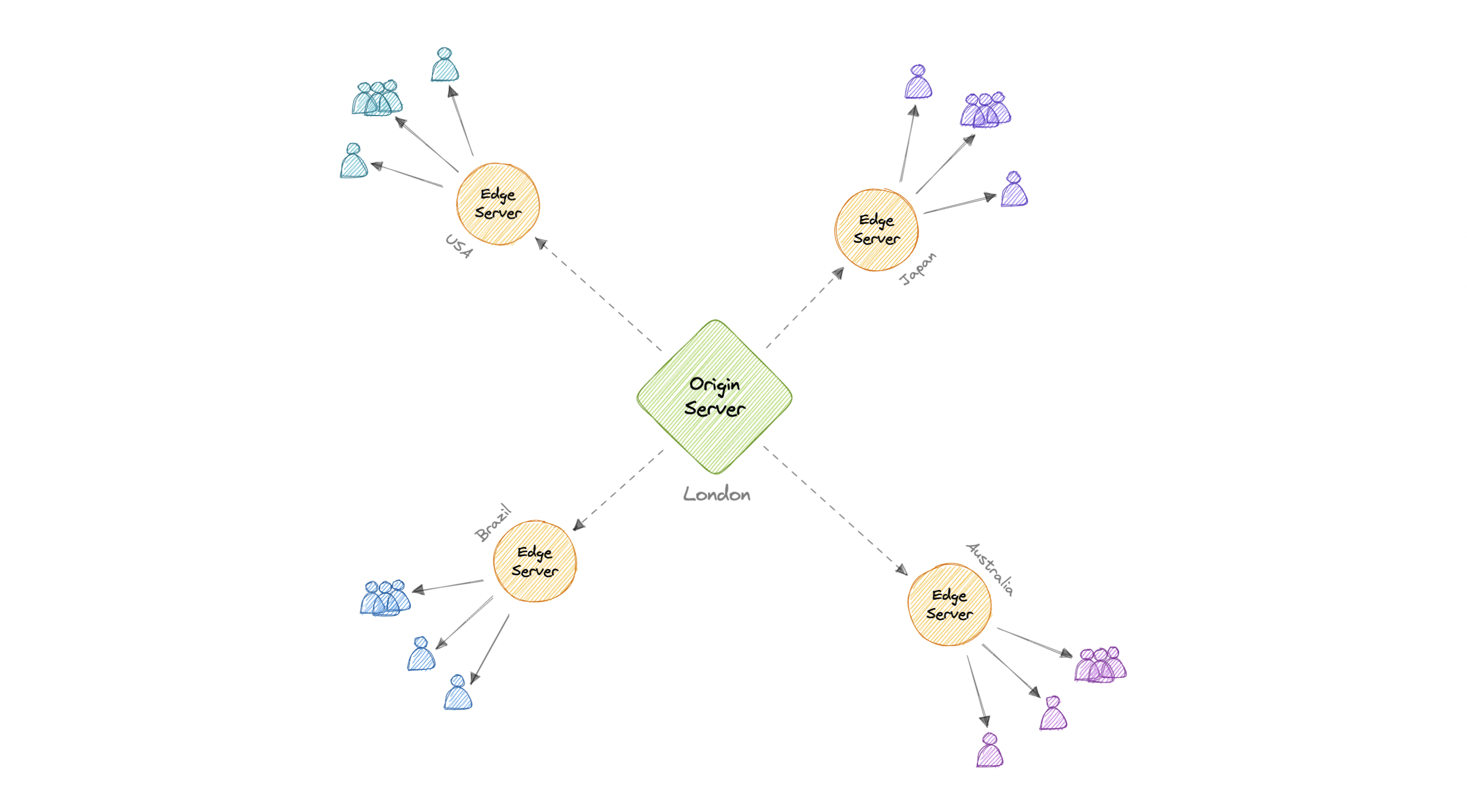
In a CDN, the origin server contains the original versions of the content while the edge servers are numerous and distributed across various locations around the world.
To minimize the distance between the visitors and the website's server, a CDN stores a cached version of its content in multiple geographical locations known as edge locations. Each edge location contains several caching servers responsible for content delivery to visitors within its proximity.
Once the static assets are cached on all the CDN servers for a particular location, all subsequent website visitor requests for static assets will be delivered from these edge servers instead of the origin, thus reducing the origin load and improving scalability.
For example, when someone in the UK requests our website which might be hosted in the USA, they will be served from the closest edge location such as the London edge location. This is much quicker than having the visitor make a complete request to the origin server which will increase the latency.
Types
CDNs are generally divided into two types:
Push CDNs
Push CDNs receive new content whenever changes occur on the server. We take full responsibility for providing content, uploading directly to the CDN, and rewriting URLs to point to the CDN. We can configure when content expires and when it is updated. Content is uploaded only when it is new or changed, minimizing traffic, but maximizing storage.
Sites with a small amount of traffic or sites with content that isn't often updated work well with push CDNs. Content is placed on the CDNs once, instead of being re-pulled at regular intervals.
Pull CDNs
In a Pull CDN situation, the cache is updated based on request. When the client sends a request that requires static assets to be fetched from the CDN if the CDN doesn't have it, then it will fetch the newly updated assets from the origin server and populate its cache with this new asset, and then send this new cached asset to the user.
Contrary to the Push CDN, this requires less maintenance because cache updates on CDN nodes are performed based on requests from the client to the origin server. Sites with heavy traffic work well with pull CDNs, as traffic is spread out more evenly with only recently-requested content remaining on the CDN.
Disadvantages
As we all know good things come with extra costs, so let's discuss some disadvantages of CDNs:
Extra charges: It can be expensive to use a CDN, especially for high-traffic services.
Restrictions: Some organizations and countries have blocked the domains or IP addresses of popular CDNs.
Location: If most of our audience is located in a country where the CDN has no servers, the data on our website may have to travel further than without using any CDN.
Examples
Here are some widely used CDNs:
Proxy
A proxy server is an intermediary piece of hardware/software sitting between the client and the backend server. It receives requests from clients and relays them to the origin servers. Typically, proxies are used to filter requests, log requests, or sometimes transform requests (by adding/removing headers, encrypting/decrypting, or compression).
Types
There are two types of proxies:
Forward Proxy
A forward proxy, often called a proxy, proxy server, or web proxy is a server that sits in front of a group of client machines. When those computers make requests to sites and services on the internet, the proxy server intercepts those requests and then communicates with web servers on behalf of those clients, like a middleman.
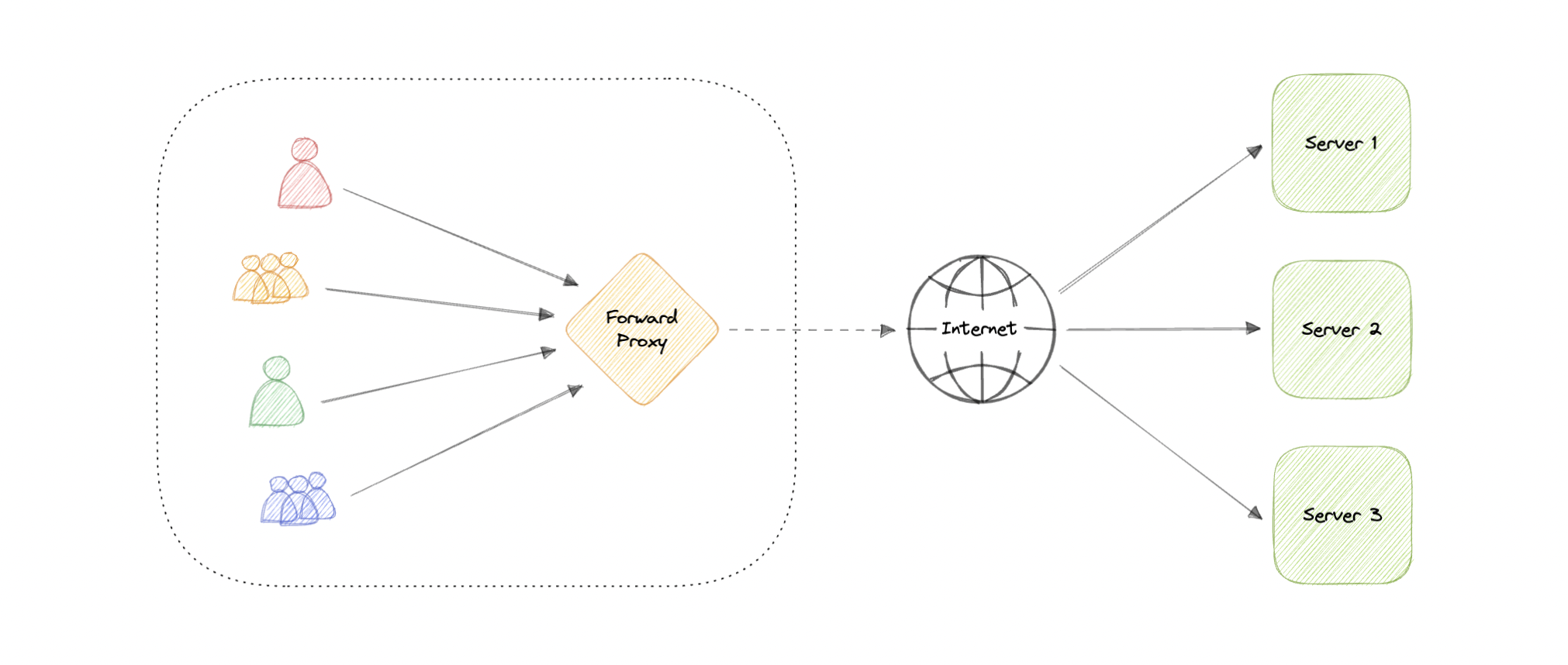
Advantages
Here are some advantages of a forward proxy:
Block access to certain content
Allows access to geo-restricted content
Provides anonymity
Avoid other browsing restrictions
Although proxies provide the benefits of anonymity, they can still track our personal information. Setup and maintenance of a proxy server can be costly and requires configurations.
Reverse Proxy
A reverse proxy is a server that sits in front of one or more web servers, intercepting requests from clients. When clients send requests to the origin server of a website, those requests are intercepted by the reverse proxy server.
The difference between a forward and reverse proxy is subtle but important. A simplified way to sum it up would be to say that a forward proxy sits in front of a client and ensures that no origin server ever communicates directly with that specific client. On the other hand, a reverse proxy sits in front of an origin server and ensures that no client ever communicates directly with that origin server.
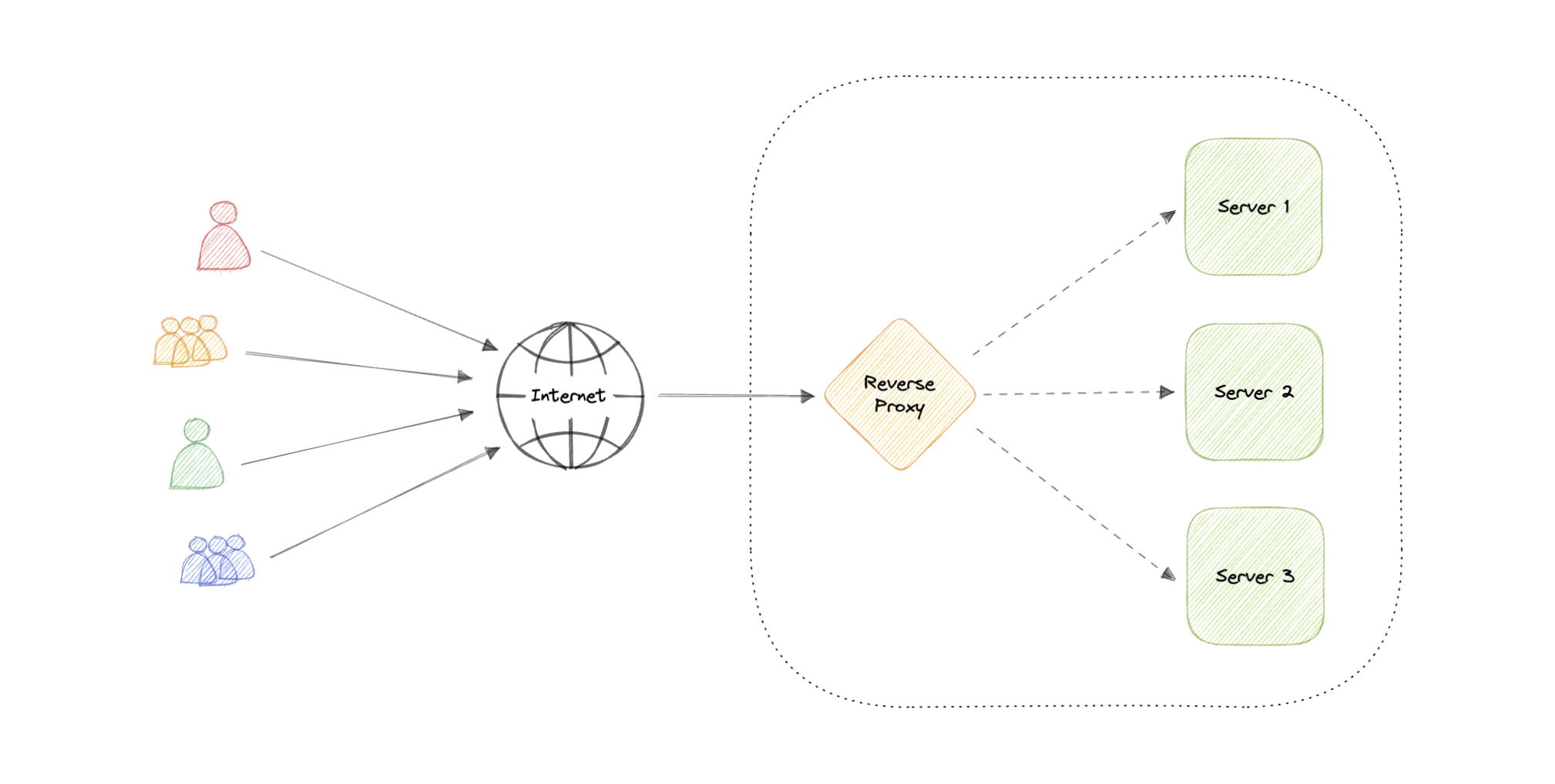
Introducing reverse proxy results in increased complexity. A single reverse proxy is a single point of failure, configuring multiple reverse proxies (i.e. a failover) further increases complexity.
Advantages
Here are some advantages of using a reverse proxy:
Load balancer vs Reverse Proxy
Wait, isn't reverse proxy similar to a load balancer? Well, no as a load balancer is useful when we have multiple servers. Often, load balancers route traffic to a set of servers serving the same function, while reverse proxies can be useful even with just one web server or application server. A reverse proxy can also act as a load balancer but not the other way around.
Examples
Below are some commonly used proxy technologies:
That's all folks.
In the next blog, I will try to cover more about Availability, Scalability, and different types of storage.
Feel free to comment on how did you like my third blog on the system design series or shoot me a mail at connect@nandan.dev If you have any queries and I will try to answer.
You can also visit my website to read some of the articles at https://nandan.dev/
Stay tuned & connect with me on my social media channels. Make sure to subscribe to my newsletter to get regular updates on my upcoming posts.
Twitter | Instagram | Github | Website







