Domain Name System (DNS)
In the last blog post, we learned about IP addresses that enable one machine to connect with another machine.
The problem with using IP addresses is that IP addresses are not very easy to remember. For us humans, It is tough to remember numbers like 122.250.192.232 because we are more comfortable with names than numbers.
So, It is easy to remember a name, something like nandan.dev than a series of numbers i.e. 185.199.111.153.
That is where Domain Name Systems (DNS) come into the picture.
What is DNS
DNS is a decentralized naming system that translates human-understandable domain names to machine-understandable Internet Protocol addresses (IP addresses).
How DNS works
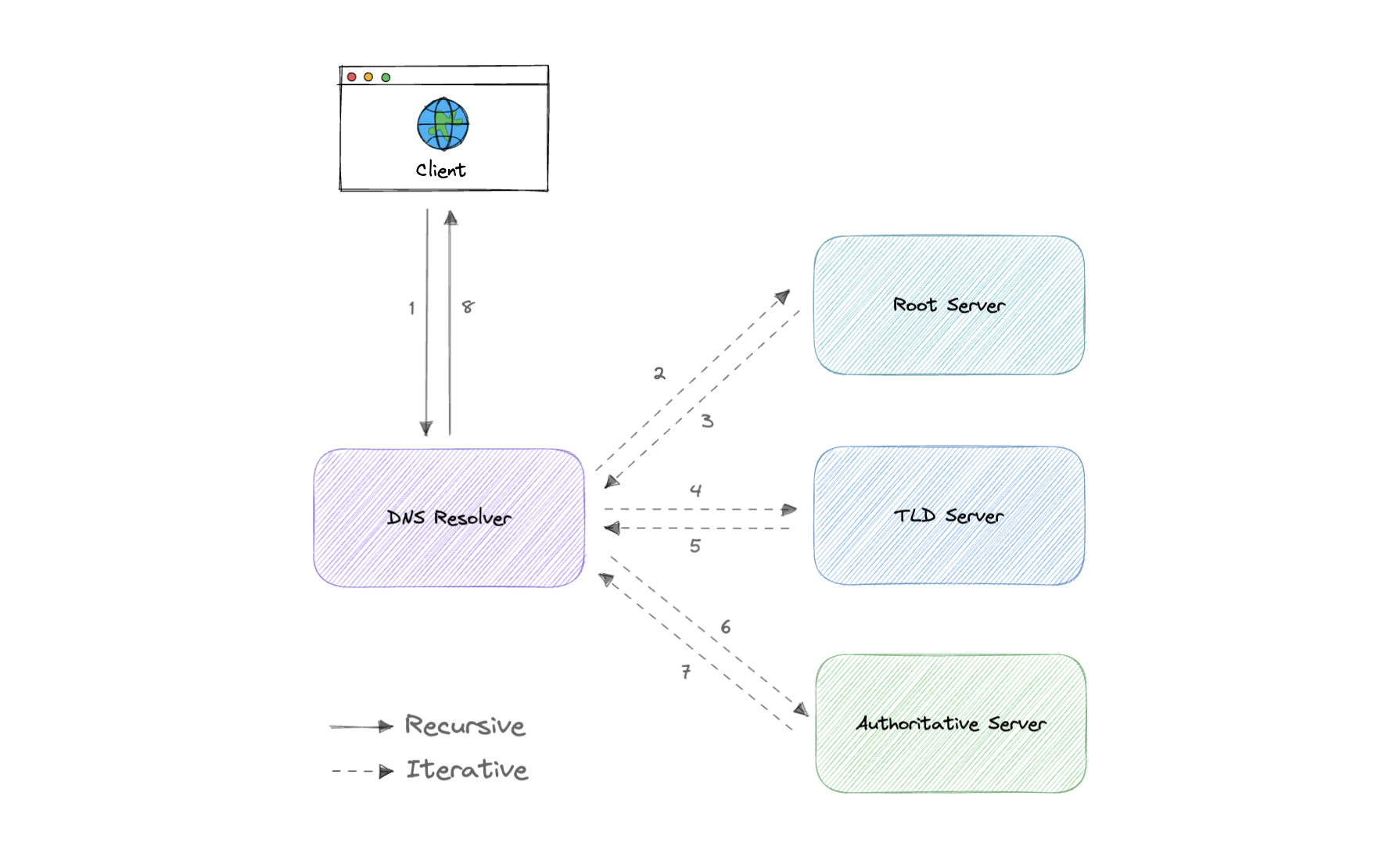
DNS lookup involves the following steps:
- When you type google.com into a web browser, the query travels through the internet and is received by a DNS resolver.
- The DNS resolver receives the query, It then recursively queries a DNS root nameserver.
- The DNS root server then responds to the resolver with the address of a Top-Level Domain (TLD).
- The resolver then makes a request to the
.com TLD.
- The TLD server then responds with the IP address of the domain's nameserver, google.com.
- Lastly, the recursive resolver sends a query to the domain's nameserver.
- The IP address for google.com is then returned to the resolver from the nameserver.
- The DNS resolver then responds to the web browser with the IP address of the domain requested initially.
Once the IP address has been resolved, the client should be able to request content from the resolved IP address. For example, the resolved IP may return a webpage to be rendered in the browser.
Server types
Now, let's look at the four key components that make up the DNS infrastructure.
DNS Resolver
A DNS resolver (also known as a DNS recursive resolver) is the first stop in a DNS query. The recursive resolver acts as a middleman between a client and a DNS nameserver. After receiving a DNS query from a web client, a recursive resolver will either respond with cached data, or send a request to a root nameserver, followed by another request to a TLD nameserver, and then one last request to an authoritative nameserver. After receiving a response from the authoritative nameserver containing the requested IP address, the recursive resolver then sends a response to the client.
DNS root server
A root server accepts a recursive resolver's query which includes a domain name, and the root nameserver responds by directing the recursive resolver to a TLD nameserver, based on the extension of that domain (.com, .net, .org, etc.). The root nameservers are overseen by a nonprofit called the Internet Corporation for Assigned Names and Numbers (ICANN).
There are 13 DNS root nameservers known to every recursive resolver. Note that while there are 13 root nameservers, that doesn't mean that there are only 13 machines in the root nameserver system. There are 13 types of root nameservers, but there are multiple copies of each one all over the world, which use Anycast routing to provide speedy responses.
TLD nameserver
A TLD nameserver maintains information for all the domain names that share a common domain extension, such as .com, .net, or whatever comes after the last dot in a URL.
Management of TLD nameservers is handled by the Internet Assigned Numbers Authority (IANA), which is a branch of ICANN. The IANA breaks up the TLD servers into two main groups:
- Generic top-level domains: These are domains like
.com, .org, .net, .edu, .info, and .gov.
- Country code top-level domains: These include any domains that are specific to a country or state. Examples include
.uk, .us, .ru, and .jp.
Authoritative DNS server
The authoritative nameserver is usually the resolver's last step in the journey for an IP address. The authoritative nameserver contains information specific to the domain name it serves (e.g. google.com) and it can provide a recursive resolver with the IP address of that server found in the DNS A record, or if the domain has a CNAME record (alias) it will provide the recursive resolver with an alias domain, at which point the recursive resolver will have to perform a whole new DNS lookup to procure a record from an authoritative nameserver (often an A record containing an IP address). If it cannot find the domain, returns the NXDOMAIN message.
Query Types
There are three types of queries in a DNS system:
Recursive
In a recursive query, a DNS client requires that a DNS server (typically a DNS recursive resolver) will respond to the client with either the requested resource record or an error message if the resolver can't find the record.
Iterative
In an iterative query, a DNS client provides a hostname, and the DNS Resolver returns the best answer it can. If the DNS resolver has the relevant DNS records in its cache, it returns them. If not, it refers the DNS client to the Root Server or another Authoritative Name Server that is nearest to the required DNS zone. The DNS client must then repeat the query directly against the DNS server it was referred.
Non-recursive
A non-recursive query is a query in which the DNS Resolver already knows the answer. It either immediately returns a DNS record because it already stores it in a local cache, or queries a DNS Name Server which is authoritative for the record, meaning it definitely holds the correct IP for that hostname. In both cases, there is no need for additional rounds of queries (like in recursive or iterative queries). Rather, a response is immediately returned to the client.
Record Types
DNS records (aka zone files) are instructions that live in authoritative DNS servers and provide information about a domain including what IP address is associated with that domain and how to handle requests for that domain.
These records consist of a series of text files written in what is known as DNS syntax. DNS syntax is just a string of characters used as commands that tell the DNS server what to do. All DNS records also have a "TTL", which stands for time-to-live, and indicates how often a DNS server will refresh that record.
Now let's look at some of the most commonly used record types:
- A (Address record): This is the record that holds the IPv4 address of a domain.
- AAAA (IP Version 6 Address record): The record that contains the IPv6 address for a domain.
- CNAME (Canonical Name record): Forwards one domain or subdomain to another domain, does NOT provide an IP address.
- MX (Mail exchanger record): Directs mail to an email server.
- TXT (Text Record): This record lets an admin store text notes in the record. These records are often used for email security.
- NS (Name Server records): Stores the name server for a DNS entry.
- SOA (Start of Authority): Stores admin information about a domain.
- SRV (Service Location record): Specifies a port for specific services.
- PTR (Reverse-lookup Pointer records): Provides a domain name in reverse lookups.
- CERT (Certificate record): Stores public key certificates.
Subdomains
A subdomain is an additional part of the main domain name. It is commonly used to logically separate a website into sections. We can create multiple subdomains or child domains on the main domain.
For example, blog.nandan.dev where blog is the subdomain, nandan is the primary domain and .info is the top-level domain (TLD). Similar examples can be store.nandan.dev. blog subdomain is separated from the main domain which is nandan.dev, and It uses a completely separate hosting service from the main domain.
I have detailed more about using subdomains to create separate sections in the blog here.
DNS Zones
A DNS zone is a distinct part of the domain namespace which is delegated to a legal entity like a person, organization, or company, who is responsible for maintaining the DNS zone. A DNS zone is also an administrative function, allowing for granular control of DNS components, such as authoritative name servers.
DNS Caching
A DNS cache (sometimes called a DNS resolver cache) is a temporary database, maintained by a computer's operating system, that contains records of all the recent visits and attempted visits to websites and other internet domains. In other words, a DNS cache is just a memory of recent DNS lookups that our computer can quickly refer to when it's trying to figure out how to load a website.
The Domain Name System implements a time-to-live (TTL) on every DNS record. TTL specifies the number of seconds the record can be cached by a DNS client or server. When the record is stored in a cache, whatever TTL value came with it gets stored as well. The server continues to update the TTL of the record stored in the cache, counting down every second. When it hits zero, the record is deleted or purged from the cache. At that point, if a query for that record is received, the DNS server has to start the resolution process.
Reverse DNS
A reverse DNS lookup is a DNS query for the domain name associated with a given IP address. This accomplishes the opposite of the more commonly used forward DNS lookup, in which the DNS system is queried to return an IP address. The process of reverse resolving an IP address uses PTR records. If the server does not have a PTR record, it cannot resolve a reverse lookup.
Reverse lookups are commonly used by email servers. Email servers check and see if an email message came from a valid server before bringing it onto their network. Many email servers will reject messages from any server that does not support reverse lookups or from a server that is highly unlikely to be legitimate.
Note: Reverse DNS lookups are not universally adopted as they are not critical to the normal function of the internet.
Examples
These are some widely used managed DNS solutions:
Load Balancing
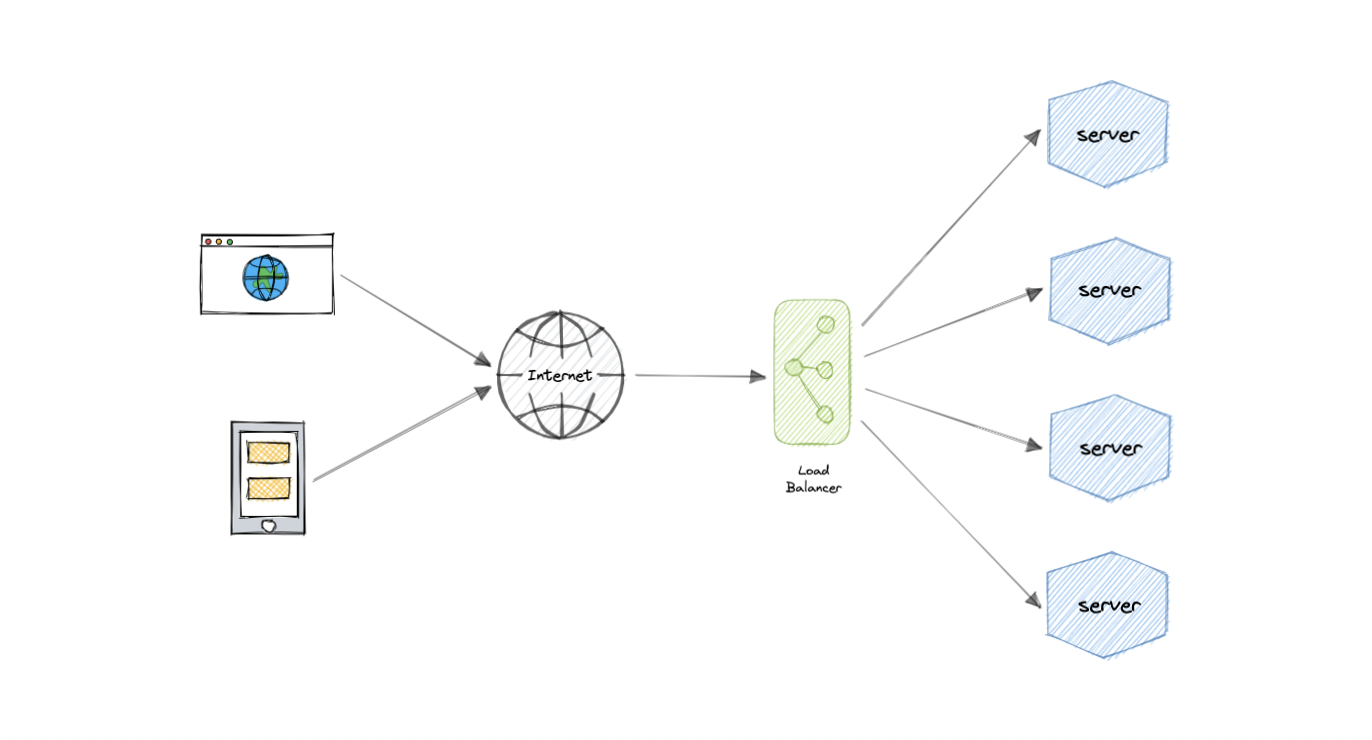
Load balancing, As the name suggests, lets us distribute incoming network traffic across multiple resources(i.e. Servers, Databases etc.) ensuring high availability and reliability by sending requests only to resources that are available and running. This provides the flexibility to add or subtract resources as demand dictates.
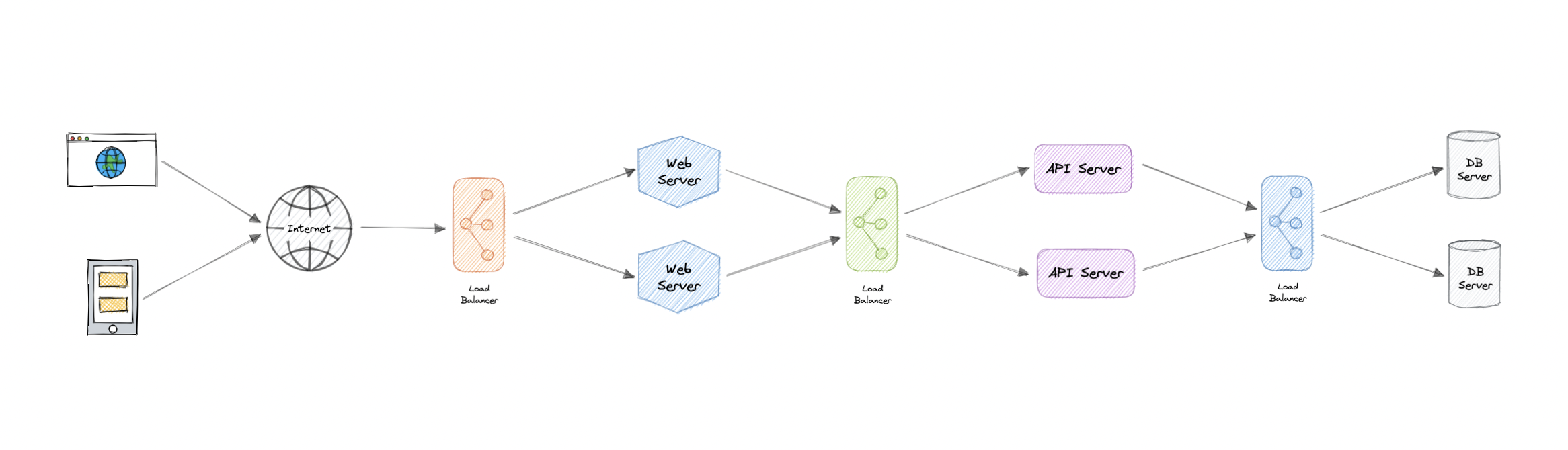
For additional scalability and redundancy, load balancing can be implemented at each layer of the system:
Let's understand why?
Modern high-traffic websites must serve thousands, if not millions, of concurrent requests from users/clients. To cost-effectively scale to meet these high volumes, modern computing best practice generally requires adding more servers and at times removing/hibernating them.
Load balancer sits in front of the servers and route client requests across all servers capable of fulfilling those requests in a way that maximizes speed(reduces turn-around time) and capacity utilization. This ensures that no single server is overburdened, which eventually can lead to degraded performance. If any of the server goes down, the load balancer redirects incoming traffic to the remaining online servers. Likewise When a new server is added or made available to the server group, the load balancer automatically starts sending requests to it.
Workload distribution
This is the core functionality provided by a load balancer and has several common variations:
- Host-based: Distributes requests based on the requested hostname.
- Path-based: Using the entire URL to distribute requests as opposed to just the hostname.
- Content-based: Inspects the message content of a request. This allows distribution based on content such as the value of a parameter.
Layers
Generally speaking, load balancers operate at one of two levels:
Network layer
This is the load balancer that works at the network's transport layer, also known as layer 4. This performs routing based on networking information such as IP addresses and is not able to perform content-based routing. These are often dedicated hardware devices that can operate at high speed.
Application layer
This is the load balancer that operates at the application layer, also known as layer 7. Load balancers can read requests in their entirety and perform content-based routing. This allows the management of load based on a full understanding of traffic.
Types
Let's look at different types of load balancers:
Software
Software load balancers usually are easier to deploy than hardware versions. They also tend to be more cost-effective and flexible, and they are used in conjunction with software development environments. The software approach gives us the flexibility of configuring the load balancer to our environment's specific needs. The boost in flexibility may come at the cost of having to do more work to set up the load balancer. Compared to hardware versions, which offer more of a closed-box approach, software balancers give us more freedom to make changes and upgrades.
Software load balancers are widely used and are available either as installable solutions that require configuration and management or as a managed cloud service.
Hardware
As the name implies, a hardware load balancer relies on physical, on-premises hardware to distribute application and network traffic. These devices can handle a large volume of traffic but often carry a hefty price tag and are fairly limited in terms of flexibility.
Hardware load balancers include proprietary firmware that requires maintenance and updates as new versions, and security patches are released.
DNS
DNS load balancing is the practice of configuring a domain in the Domain Name System (DNS) such that client requests to the domain are distributed across a group of server machines.
Unfortunately, DNS load balancing has inherent problems limiting its reliability and efficiency. Most significantly, DNS does not check for server and network outages, or errors. It always returns the same set of IP addresses for a domain even if servers are down or inaccessible.
Routing Algorithms
Now, let's discuss commonly used routing algorithms:
- Round-robin: Requests are distributed to application servers in rotation.
- Weighted Round-robin: Builds on the simple Round-robin technique to account for differing server characteristics such as compute and traffic handling capacity using weights that can be assigned via DNS records by the administrator.
- Least Connections: A new request is sent to the server with the fewest current connections to clients. The relative computing capacity of each server is factored into determining which one has the least connections.
- Least Response Time: Sends requests to the server selected by a formula that combines the fastest response time and fewest active connections.
- Least Bandwidth: This method measures traffic in megabits per second (Mbps), sending client requests to the server with the least Mbps of traffic.
- Hashing: Distributes requests based on a key we define, such as the client IP address or the request URL.
Advantages
Load balancing also plays a key role in preventing downtime, other advantages of load balancing include the following:
- Scalability
- Redundancy
- Flexibility
- Efficiency
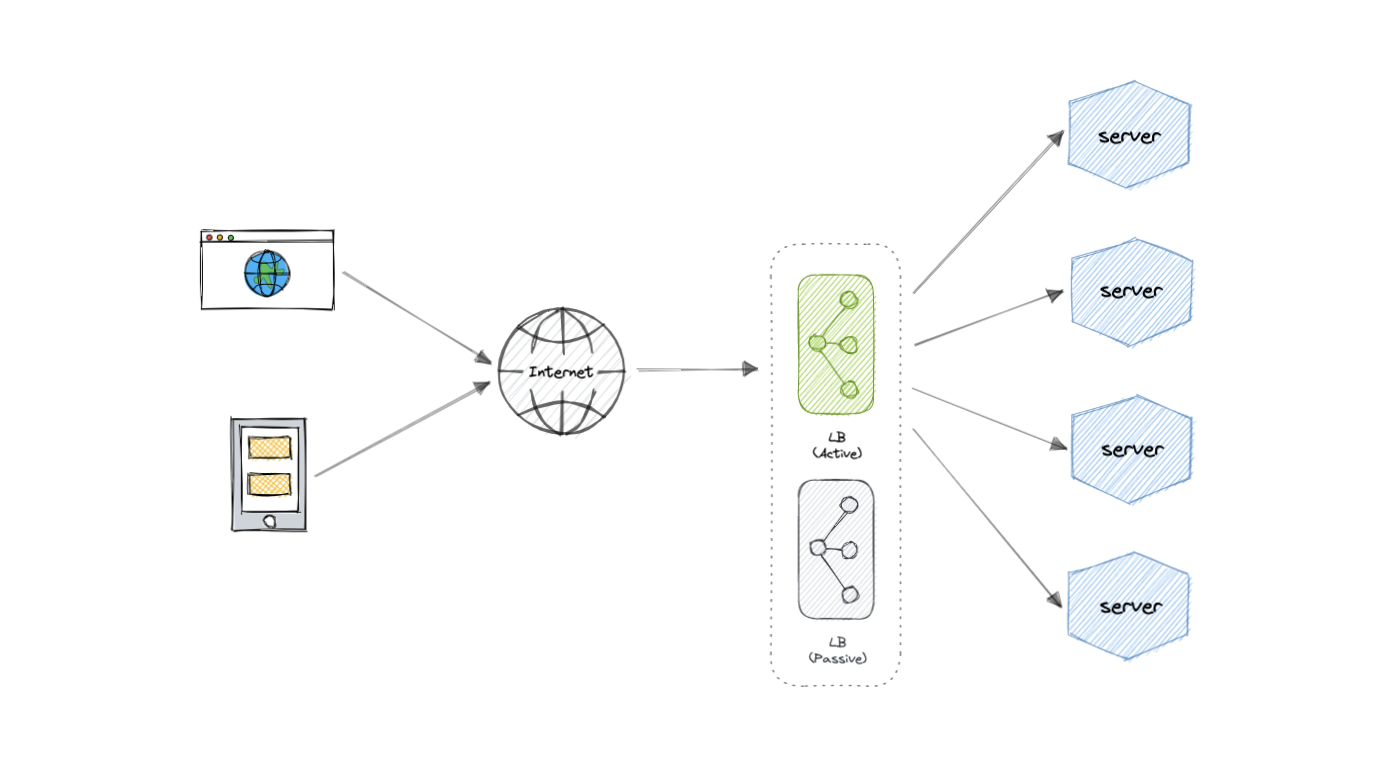
Redundant load balancers
As you must've already guessed, the load balancer itself can be a single point of failure. To overcome this, a second or N number of load balancers can be used in a cluster mode.
And, if there's a failure detection and the active load balancer fails, another passive load balancer can take over which will make our system more fault-tolerant.
Features
Here are some commonly desired features of load balancers:
- Autoscaling: Starting up and shutting down resources in response to demand conditions.
- Sticky sessions: The ability to assign the same user or device to the same resource in order to maintain the session state on the resource.
- Healthchecks: The ability to determine if a resource is down or performing poorly in order to remove the resource from the load balancing pool.
- Persistence connections: Allowing a server to open a persistent connection with a client such as a WebSocket.
- Encryption: Handling encrypted connections such as TLS and SSL.
- Certificates: Presenting certificates to a client and authentication of client certificates.
- Compression: Compression of responses.
- Caching: An application-layer load balancer may offer the ability to cache responses.
- Logging: Logging of request and response metadata can serve as an important audit trail or source for analytics data.
- Request tracing: Assigning each request a unique id for the purposes of logging, monitoring, and troubleshooting.
- Redirects: The ability to redirect an incoming request based on factors such as the requested path.
- Fixed response: Returning a static response for a request such as an error message.
Examples
Following are some of the load-balancing solutions commonly used in the industry:
Clustering
At a high level, a computer cluster is a group of two or more computers, or nodes, that run in parallel to achieve a common goal. This allows workloads consisting of a high number of individual, parallelizable tasks to be distributed among the nodes in the cluster. As a result, these tasks can leverage the combined memory and processing power of each computer to increase overall performance.
To build a computer cluster, the individual nodes should be connected to a network to enable internode communication. The software can then be used to join the nodes together and form a cluster. It may have a shared storage device and/or local storage on each node.
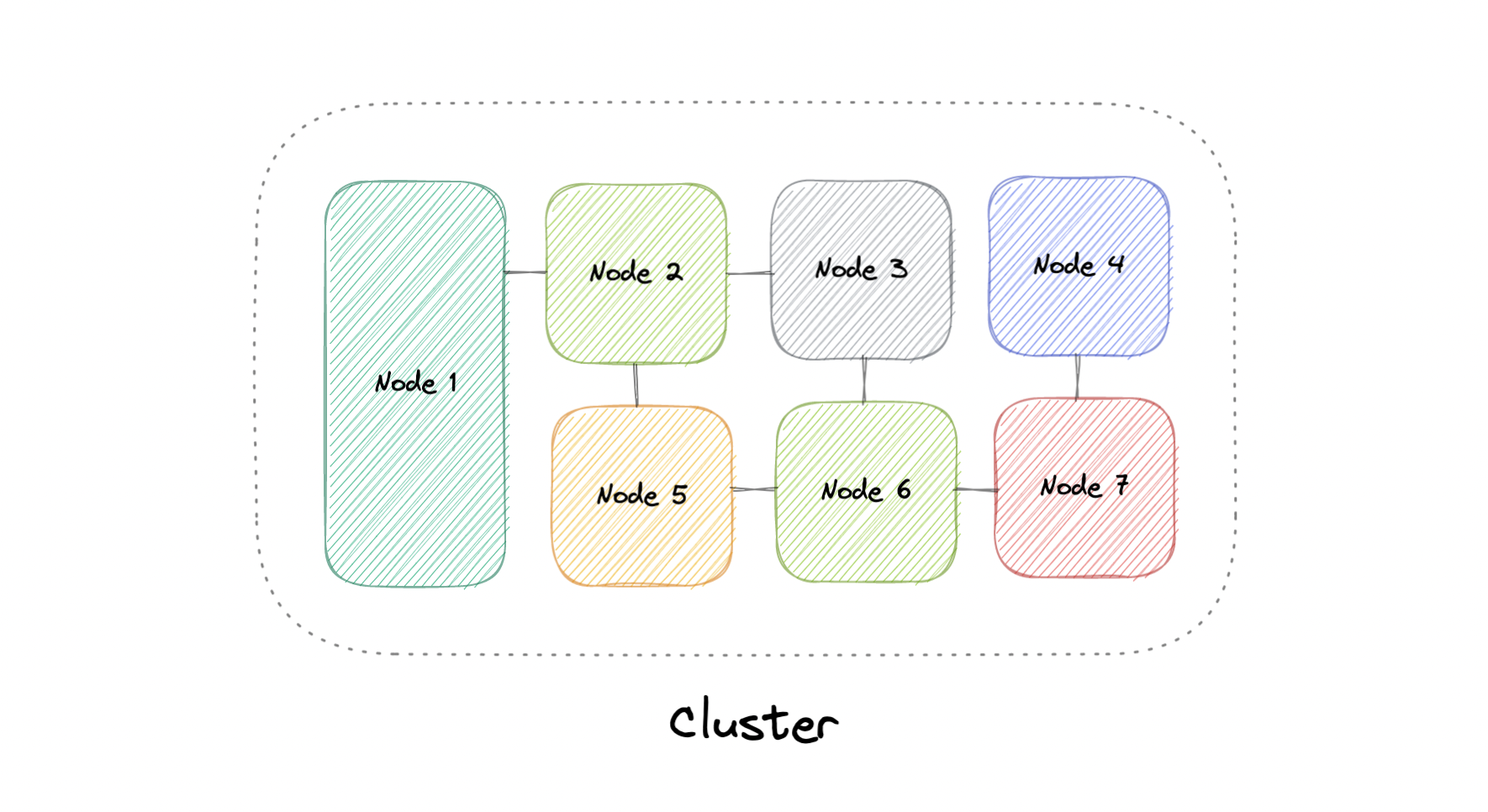
Typically, at least one node is designated as the leader node and acts as the entry point to the cluster. The leader node may be responsible for delegating incoming work to the other nodes and, if necessary, aggregating the results and returning a response to the user.
Ideally, a cluster functions as if it were a single system. A user accessing the cluster should not need to know whether the system is a cluster or an individual machine. Furthermore, a cluster should be designed to minimize latency and prevent bottlenecks in node-to-node communication.
Types
Computer clusters can generally be categorized into three types:
- Highly available or fail-over
- Load balancing
- High-performance computing
Configurations
The two most commonly used high availability (HA) clustering configurations are active-active and active-passive.
Active-Active
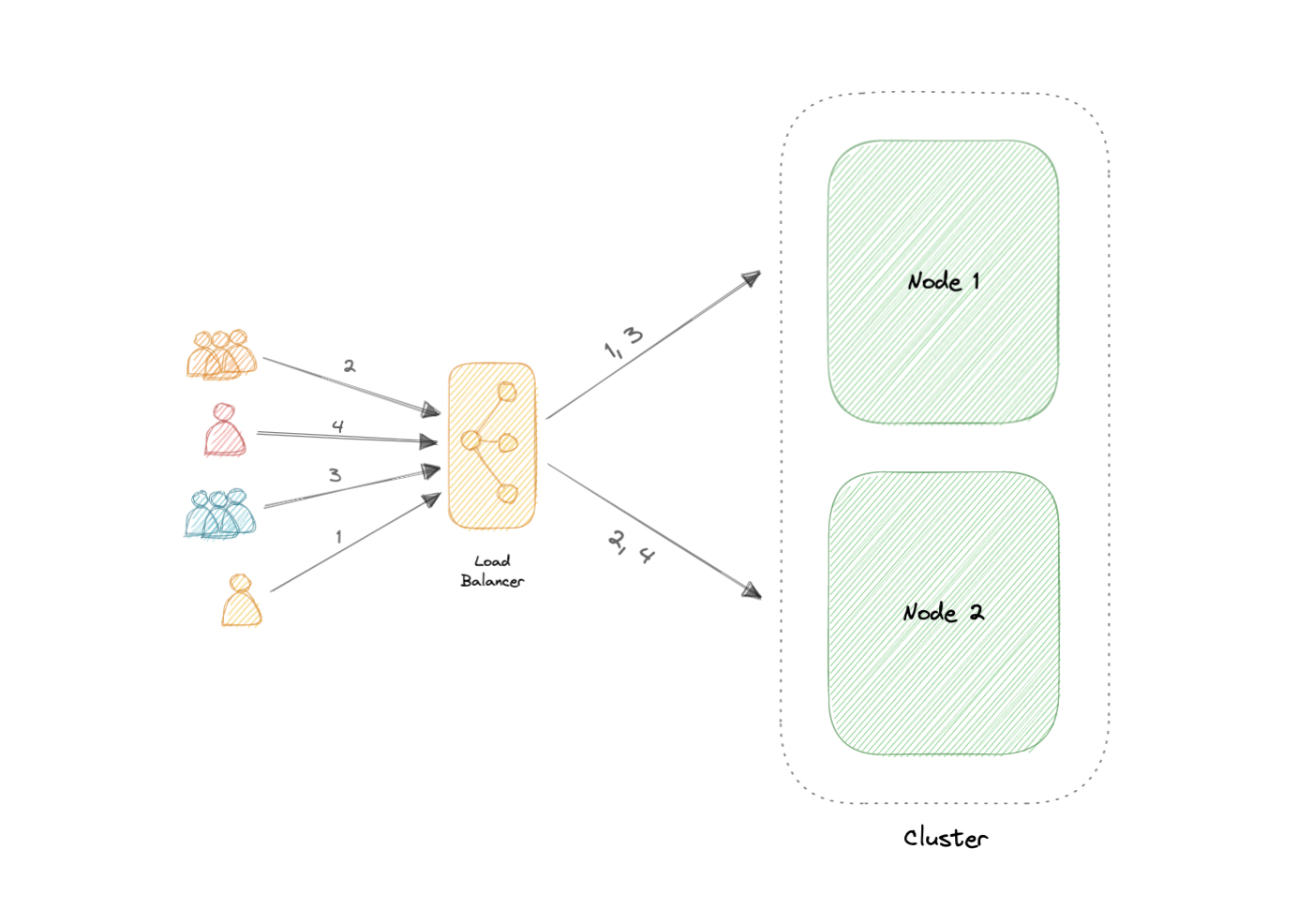
An active-active cluster is typically made up of at least two nodes, both actively running the same kind of service simultaneously. The main purpose of an active-active cluster is to achieve load balancing. A load balancer distributes workloads across all nodes to prevent any single node from getting overloaded. Because there are more nodes available to serve, there will also be an improvement in throughput and response times.
Active-Passive
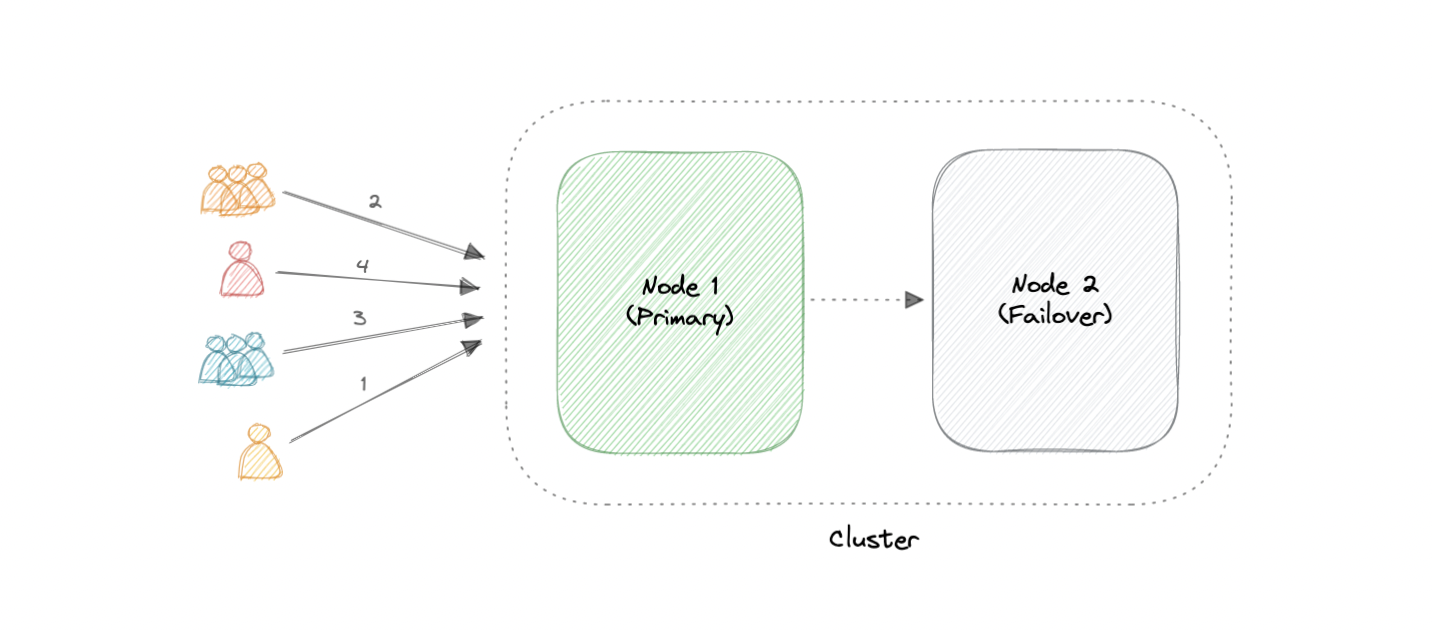
Like the active-active cluster configuration, an active-passive cluster also consists of at least two nodes. However, as the name active-passive implies, not all nodes are going to be active. For example, in the case of two nodes, if the first node is already active, then the second node must be passive or on standby.
Advantages
Four key advantages of cluster computing are as follows:
- High availability
- Scalability
- Performance
- Cost-effective
Load balancing vs Clustering
Load balancing shares some common traits with clustering, but they are different processes. Clustering provides redundancy and boosts capacity and availability. Servers in a cluster are aware of each other and work together toward a common purpose. But with load balancing, servers are not aware of each other. Instead, they react to the requests they receive from the load balancer.
We can employ load balancing in conjunction with clustering, but it also is applicable in cases involving independent servers that share a common purpose such as to run a website, business application, web service, or some other IT resource.
Challenges
The most obvious challenge clustering presents is the increased complexity of installation and maintenance. An operating system, the application, and its dependencies must each be installed and updated on every node.
This becomes even more complicated if the nodes in the cluster are not homogeneous. Resource utilization for each node must also be closely monitored, and logs should be aggregated to ensure that the software is behaving correctly.
Additionally, storage becomes more difficult to manage, a shared storage device must prevent nodes from overwriting one another and distributed data stores have to be kept in sync.
Examples
Clustering is commonly used in the industry, and often many technologies offer some sort of clustering mode. For example:
That's all folks.
In the next blog, I will try to cover more about Caching, CDNs, Proxy servers etc.
Feel free to comment on how did you like my first blog on the system design series or shoot me a mail at [connect@nandan.dev](mailto:connect@nandan.dev If you have any queries and I will try to answer.
You can also visit my website to read some of the articles at https://nandan.dev/
Stay tuned & connect with me on my social media channels. Make sure to subscribe to my newsletter to get regular updates on my upcoming posts.
Twitter | Instagram | Github | Website







