Availability
Availability refers to the duration for which a system performs its intended function within a given timeframe. It measures the percentage of time a system or machine remains operational under normal circumstances, serving as a simple metric of operational continuity.
The Nine’s of availability
The "Nine's of availability" is a way to measure the reliability and uptime of a system. It is expressed as a percentage or number of nines, where each "nine" represents an additional decimal place of uptime.
$$Availability = \frac{Uptime}{(Uptime + Downtime)}$$
If availability is 99.00% available, it is said to have “2 nines” of availability, and if it is 99.9%, it is called “3 nines”, and so on.
| Availability (Percent) | Downtime (Year) | Downtime (Month) | Downtime (Week) |
| 90% (one nine) | 36.53 days | 72 hours | 16.8 hours |
| 99% (two nines) | 3.65 days | 7.20 hours | 1.68 hours |
| 99.9% (three nines) | 8.77 hours | 43.8 minutes | 10.1 minutes |
| 99.99% (four nines) | 52.6 minutes | 4.32 minutes | 1.01 minutes |
| 99.999% (five nines) | 5.25 minutes | 25.9 seconds | 6.05 seconds |
| 99.9999% (six nines) | 31.56 seconds | 2.59 seconds | 604.8 milliseconds |
| 99.99999% (seven nines) | 3.15 seconds | 263 milliseconds | 60.5 milliseconds |
| 99.999999% (eight nines) | 315.6 milliseconds | 26.3 milliseconds | 6 milliseconds |
| 99.9999999% (nine nines) | 31.6 milliseconds | 2.6 milliseconds | 0.6 milliseconds |
Availability in Sequence vs Parallel
If a service consists of multiple components prone to failure, the service’s overall availability depends on whether the components are in sequence or in parallel.
Sequence
Overall availability decreases when two components are in sequence.
$$Availability \space (Total) = Availability \space (Foo) * Availability \space (Bar)$$
For example, if both Foo and Bar each had 99.9% availability, their total availability in sequence would be 99.8%.
Parallel
Overall availability increases when two components are in parallel.
$$Availability \space (Total) = 1 - (1 - Availability \space (Foo)) * (1 - Availability \space (Bar))$$
For example, if both Foo and Bar each had 99.9% availability, their total availability in parallel would be 99.9999%.
Availability vs Reliability
If a system is reliable, it means it is available. However, if a system is available, it does not necessarily mean it is reliable. This means that a system with high reliability will also have high availability, but a system can still achieve high availability without being reliable.
High Availability vs Fault Tolerance
Both high availability and fault tolerance are methods for achieving high uptime levels, but they work differently.
A fault-tolerant system ensures that there is no service interruption, but it comes at a higher cost. On the other hand, a highly available system minimizes service interruption. To achieve fault tolerance, hardware redundancy is essential. In case the main system fails, another system takes over without any loss in uptime.
Scalability
Scalability is the measure of how well a system responds to changes by adding or removing resources to meet demands.
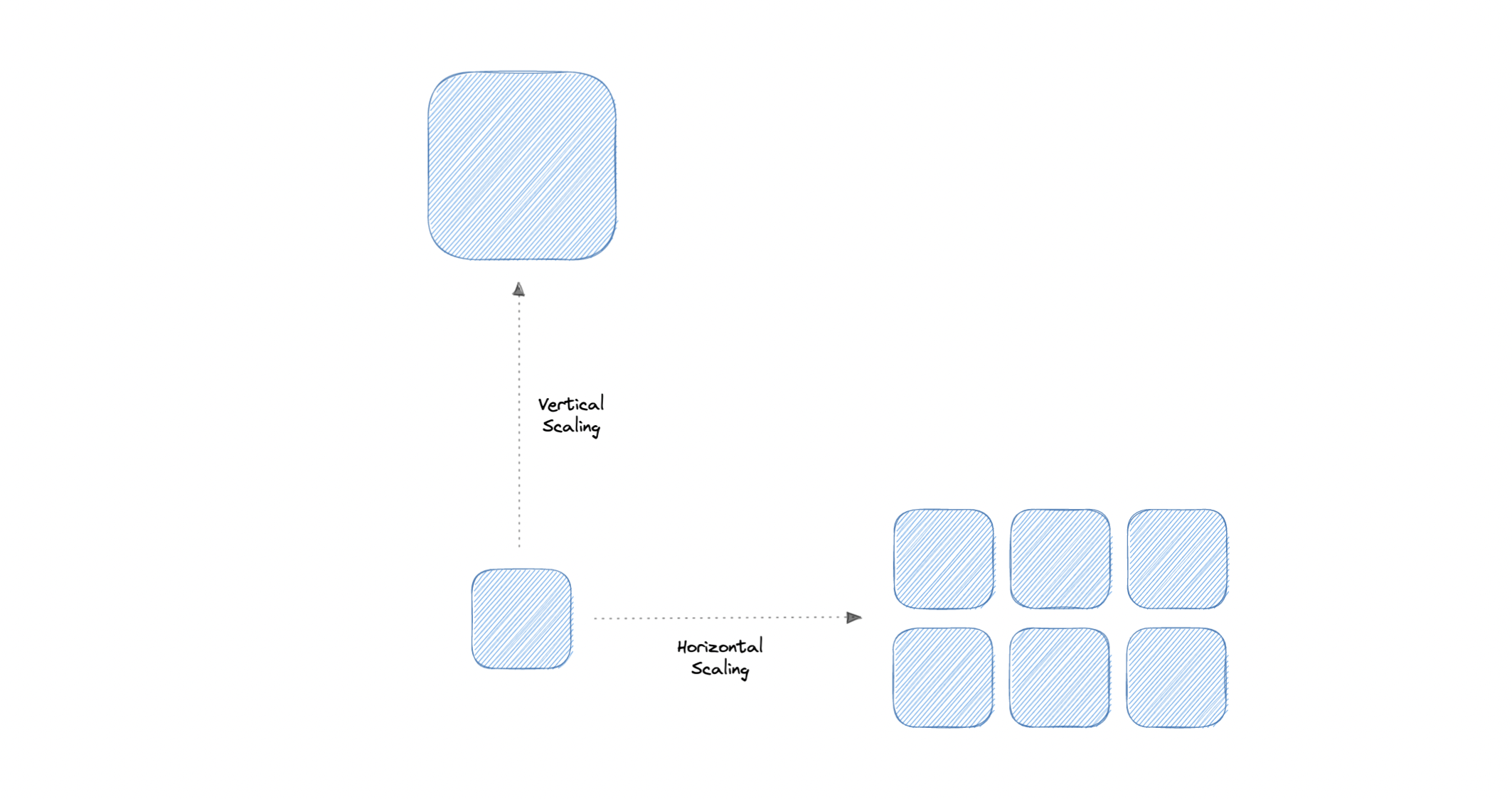
Let’s discuss different types of scaling:
Vertical scaling
Vertical scaling (also known as scaling up) expands a system’s scalability by adding more power to an existing machine. In other words, vertical scaling refers to improving an application’s capability via increasing hardware capacity.
Advantages
Simple to implement
Easier to manage
Data consistent
Disadvantages
Horizontal scaling
Horizontal scaling (also known as scaling out) expands a system’s scale by adding more machines. It improves the performance of the server by adding more instances to the existing pool of servers, allowing the load to be distributed more evenly.
Advantages
Increased redundancy
Better fault tolerance
Flexible and efficient
Easier to upgrade
Disadvantages
Storage
Storage is a mechanism that enables a system to retain data, either temporarily or permanently. This topic is mostly skipped over in the context of system design, however, it is important to have a basic understanding of some common types of storage techniques that can help us fine-tune our storage components. Let’s discuss some important storage concepts:
RAID
RAID (Redundant Array of Independent Disks) is a way of storing the same data on multiple hard disks or solid-state drives (SSDs) to protect data in the case of a drive failure.
There are different RAID levels, however, and not all have the goal of providing redundancy. Let’s discuss some commonly used RAID levels:
RAID 0: Also known as striping, data is split evenly across all the drives in the array.
RAID 1: Also known as mirroring, at least two drives contains the exact copy of a set of data. If a drive fails, others will still work.
RAID 5: Striping with parity. Requires the use of at least 3 drives, striping the data across multiple drives like RAID 0, but also has a parity distributed across the drives.
RAID 6: Striping with double parity. RAID 6 is like RAID 5, but the parity data are written to two drives.
RAID 10: Combines striping plus mirroring from RAID 0 and RAID 1. It provides security by mirroring all data on secondary drives while using striping across each set of drives to speed up data transfers.
Comparison
Let’s compare all the features of different RAID levels:
| Features | RAID 0 | RAID 1 | RAID 5 | RAID 6 | RAID 10 |
| Description | Striping | Mirroring | Striping with Parity | Striping with double parity | Striping and Mirroring |
| Minimum Disks | 2 | 2 | 3 | 4 | 4 |
| Read Performance | High | High | High | High | High |
| Write Performance | High | Medium | High | High | Medium |
| Cost | Low | High | Low | Low | High |
| Fault Tolerance | None | Single-drive failure | Single-drive failure | Two-drive failure | Up to one disk failure in each sub-array |
| Capacity Utilization | 100% | 50% | 67%-94% | 50%-80% | 50% |
Volumes
"Volume" refers to a fixed amount of storage space on a disk or tape. Although the term "volume" is often used interchangeably with "storage," it is important to note that a single disk can contain multiple volumes, or a volume can span across multiple disks.
File storage
File storage is a method used to store data in a hierarchical directory structure and present it to users. It is a user-friendly solution that provides easy storage and retrieval of files. In order to locate a file in file storage, one must know the complete path of the file. It is an economical and well-structured method that is commonly used on hard drives. This means that files appear exactly the same for the user and on the hard drive.
Example: Amazon EFS, Azure files, Google Cloud Filestore, etc.
Block storage
Block storage is a method of storing data by dividing it into blocks or chunks, which are then stored as separate entities. Each block is given a unique identifier, which enables the system to store the smaller pieces of data wherever it is most convenient.
Block storage separates data from user environments, making it possible for data to be spread across multiple environments. This creates multiple paths to the data and enables users to retrieve it quickly. When a user or application requests data from the block storage system, the system reassembles the data blocks and presents the data to the user or application.
Example: Amazon EBS.
Object Storage
Object storage, also known as object-based storage, divides data files into smaller units called objects. These objects are then stored in a single repository that can be distributed across multiple networked systems.
Example: Amazon S3, Azure Blob Storage, Google Cloud Storage, etc.
NAS
A Network Attached Storage (NAS) is a device that is connected to a network and allows authorized users to store and retrieve data from a central location. The NAS device is flexible, which means that we can easily add more storage capacity as needed. It is faster and less expensive than using a public cloud service, and it provides all the benefits of cloud storage while giving us complete control over our data.
HDFS
The Hadoop Distributed File System (HDFS) is a file system that can be distributed across multiple machines in a cluster. It's designed to run on inexpensive hardware and is highly fault-tolerant. HDFS offers high-throughput access to large datasets, making it ideal for applications that require handling of massive data.
HDFS uses a block-based approach for storing files. Each file is divided into a sequence of blocks, with all blocks in a file (except the last one) being of the same size. For reliability, the blocks of a file are replicated across different machines in the cluster.
That's all folks.
In the next blog, I will try to cover more about Databases.
Feel free to comment on how you like my blog on the system design series or shoot me a mail at connect@nandan.dev If you have any queries I will try to answer.
You can also visit my website to read some of the articles at https://nandan.dev/
Stay tuned & connect with me on my social media channels. Subscribe to my newsletter to get regular updates on my upcoming posts.
If you're interested in learning about system design, you can join Design Guru's course on System Design Fundamentals.
Twitter | Instagram | Github | Website







