


NLP: A Beginner's Guide to Large Language Models, Transformers, and Fine-tuning.
A comprehensive overview of the latest NLP concepts including Large Language Models (LLMs), Transformers, etc.


Learning is challenging in your late 20s, You are adulting i.e. you have to take care of house chores, complete office work, try to get some workout done and then in your spare time, you fire up your laptop to start learning.
I got the opportunity to learn about large language models recently and I have been thinking of writing about it since then.
While you may have read many blogs on large language models (LLM). This is yet another blog talking about the same topic that has been discussed in various forums in the past few weeks and has been in the news for quite some time now.
So Let's get going.
What is a Large Language Model?
A large language model (LLM) is a type of artificial intelligence (AI) that can generate text, translate sentences from one language to another, write different kinds of creative content, and answer your questions in an informative way.
Training a Large Language Model.
LLMs are trained on massive datasets available over the internet. The "large" in the large language model refers to the number of adjustable parameters in the model. The more parameters a model has, the more complex it is and the more data it can learn from. Some of the most successful LLMs have hundreds of billions of parameters, which allows them to learn from massive datasets and perform complex tasks.
Here is an analogy that may help to explain this concept:
Imagine a model with only a few parameters. This model would be like a simple machine with a few moving parts. It could only perform simple tasks, such as adding two numbers together.
Now imagine a model with hundreds of billions of parameters. This model would be like a complex machine with thousands of moving parts. It could perform much more complex tasks, such as translating languages or writing creative content.
The more parameters a model has, the more complex it is and the more data it can learn from. This allows LLMs to perform complex tasks that would be impossible for smaller models.
Some of The most well-known examples of large language models:
GPT
BERT
BARD
What is Transformer?
Most LLMs are pre-trained on a large, general-purpose dataset and Can be fine-tuned further to be used for specific cases. All this could be possible because of the transformer architecture.
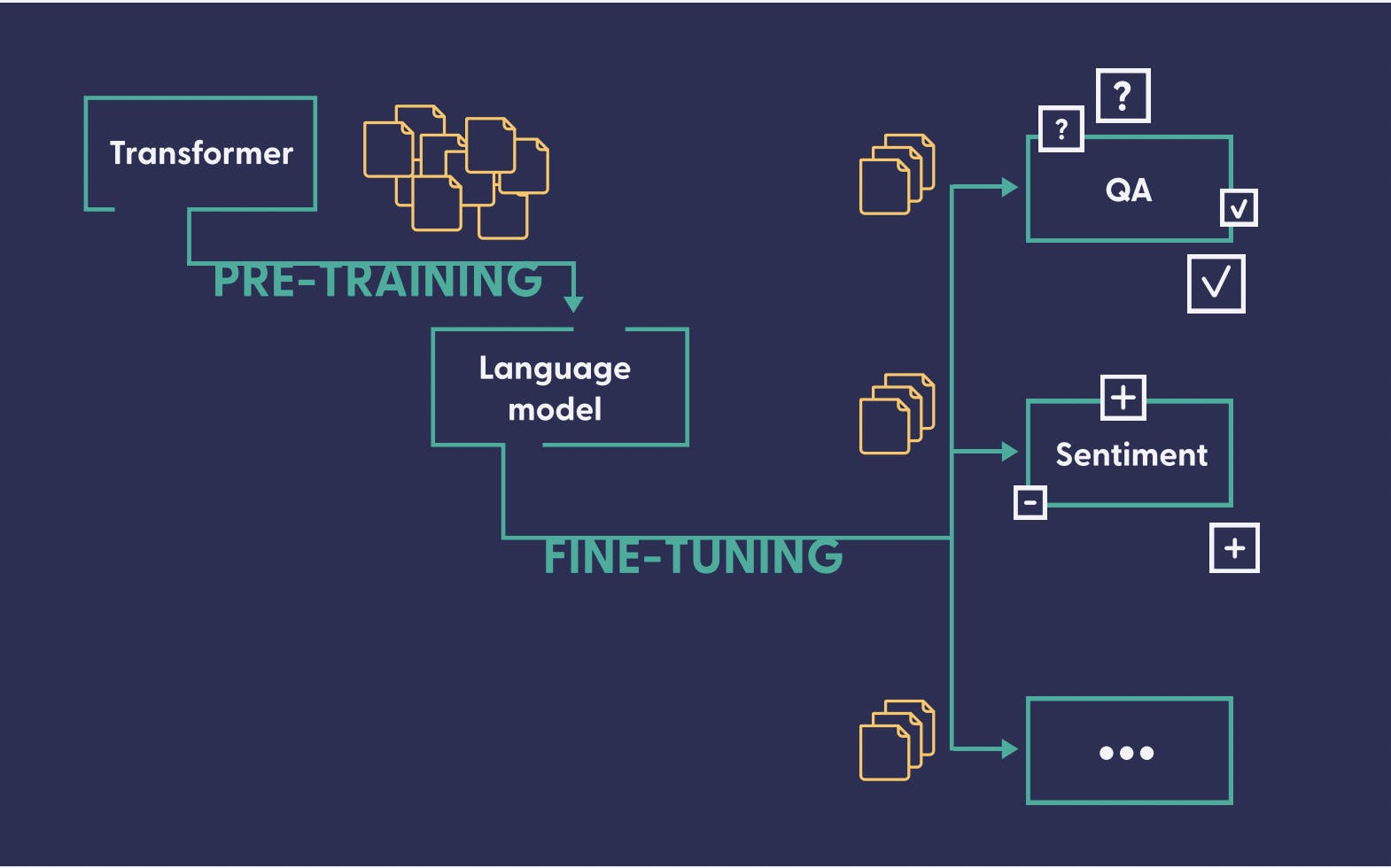
Transformers are a type of neural network architecture that is used for natural language processing (NLP) tasks. They were first introduced in the paper "Attention Is All You Need" by Vaswani et al. (2017).
Transformers work by using self-attention mechanisms to learn long-range dependencies in sequences. This makes them much more powerful than traditional neural network architectures, such as recurrent neural networks (RNNs), for NLP tasks.
The transformer architecture has made the wide adaptability of LLMs possible. It has made the training of the models progressive in the sense that someone creating a model may not have to train the model completely from scratch and they can use a pre-trained model to fine-tune them to perform their specific task.
What is Fine-Tuning?
Fine-tuning is a process in which a pre-trained large language model (LLM) is further trained on a smaller, task-specific dataset. This allows the model to learn the specific features of the task and improve its performance.
Let's take the example of creating a chatbot that can answer all the queries related to one specific set of documents. Assume these documents are proprietary and are not available over the Internet.

Someone can fine-tune an existing LLM by feeding the data specific to these documents and with some iterations of training, the Model will start answering questions related to these documents.
Here are some of the benefits of fine-tuning LLMs:
It can improve the performance of an LLM on a specific task.
It can be used to adapt an LLM to a new domain or task.
It can be used to improve the accuracy and reliability of an LLM.
Here are some of the challenges of fine-tuning LLMs:
It can be time-consuming and computationally expensive.
It can be difficult to find a task-specific dataset that is large enough and high-quality enough to train the LLM.
It can be difficult to tune the hyperparameters of the fine-tuning process.
In this blog, I have covered the basics of LLMs and How LLMs work. In my next blog, I will try to cover different types of transformers and different components of the transformer model.
That's all folks for now.
Feel free to comment on how you like my blog or shoot me a mail at connect@nandan.dev If you have any queries and I will try to answer.
You can also visit my website to read some of the articles at nandan.dev
Stay tuned & connect with me on my social media channels. Make sure to subscribe to my newsletter to get regular updates on my upcoming posts.